Faculty: Mark Hasegawa-Johnson and Yigal Brandman
Students:Mohamed Omar and Ken Chen
Sponsor: Phonetact, Incorporated
Performance Dates:August 2000 – May 2002
Human speech recognition performance is essentially unaffected by noise at signal to noise ratios above -10dB, but automatic speech recognizers suffer catastrophic failure at about 15dB SNR. Psychological research indicates that human speech recognition is more robust in part because it is based on a much richer representation of the signal in each auditory critical band. Phonetact, Inc. has proposed a set of “FM features” that show unprecedented robustness to noise at SNR as low as -10dB. Research at the University of Illinois demonstrates novel information-theoretic feature selection algorithmscapable of drawing the optimum feature set, at any given SNR, from a large list of candidate features, including the FM features. Features designed in this way lead to reduced recognition error rates at every noise level.
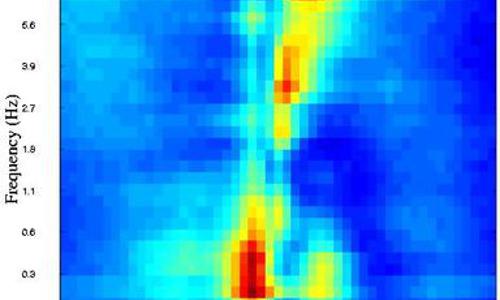
How can you select, from a large list of possible acoustic features, the acoustic features that will be most useful for a particular phonetic distinction? This paper describes a method based on mutual information. The map of mutual information versus time and frequency is called an infogram. Below are a few examples, all of which may be downloaded from here.














































































