Overview
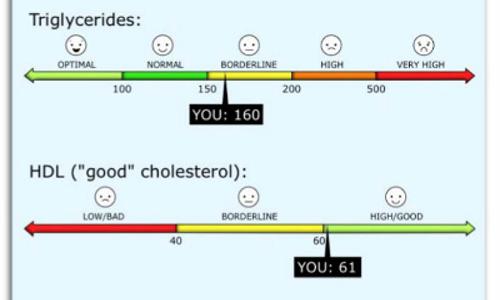
This project emulates, in a Patient Portal environment, best practices in face-to-face patient/clinician consultations. Self-managing health often hinges on patients’ comprehension of and reasoning about numeric information such as lipid panel results. This especially challenges patients with limited numeracy. Such patients are more likely to misunderstand test results, which undermines health decisions, behaviors and outcomes. Technologies such as Patient Portals, though intended to help patients, may exacerbate this problem by expanding delivery of numeric information. Clinicians are traditionally a key to helping patients create gist representations by providing a context for interpreting numeric information. They do so through verbal (evaluative commentary) and nonverbal strategies (e.g., facial expressions and prosody) that help patients understand and act. Such strategies are associated with better health behaviors and outcomes. Our team has developed a CA with stress/intonation, facial expressions and other nonverbal cues to convey affective information; by using tools developed in that prior research together with new data, we expect to develop a CA that can interact with patients in a Collaborative Patient Portal, providing succinct interpretations of test results that help patients to understand the gist of their test results.
Publications
Funded by this grant
- Renato F. L. Azevedo, Daniel Morrow, Mark Hasegawa-Johnson, Kuangxiao Gu, Dan Soberal, Thomas Huang, William Schuh , Rocio Garcia-Retamero, “Improving Patient Comprehension of Numeric Health Information,” Human Factors Conference, 2015
- Yang Zhang, Nasser Nasrabadi and Mark Hasegawa-Johnson, “Multichannel Transient Acoustic Signal Classification Using Task-Driven Dictionary with Joint Sparsity and Beamforming,” Proc. ICASSP 2015, 2591:1-5
Relevant prior work by this team
- Yang Zhang, Zhijian Ou and Mark Hasegawa-Johnson, “Incorporating AM-FM effect in voiced speech for probabilistic acoustic tube model,” Proc. WASPAA 2015
- Yang Zhang, Zhijian Ou, and Mark Hasegawa-Johnson, Improvement of Probabilistic Acoustic Tube Model for Speech Decomposition, ICASSP 2014
- Xiaodan Zhuang, Lijuan Wang, Frank Soong, and Mark Hasegawa-Johnson, A Minimum Converted Trajectory Error (MCTE) Approach to High Quality Speech-to-Lips Conversion, Proceedings of Interspeech 2010 pp. 1736-1739, (NSF 0703624)
- Thomas S. Huang, Mark A. Hasegawa-Johnson, Stephen M. Chu, Zhihong Zeng, and Hao Tang, Sensitive Talking Heads, IEEE Signal Processing Magazine 26(4):67-72, July 2009
- Hao Tang, Yun Fu, Jilin Tu, Mark Hasegawa-Johnson, and Thomas S. Huang, Humanoid Audio-Visual Avatar with Emotive Text-to-Speech Synthesis, IEEE Trans. Multimedia 10(6):969-981, 2008
- Hao Tang, Yuxiao Hu, Yun Fu, Mark Hasegawa-Johnson and Thomas S. Huang, Real-time conversion from a single 2D face image to a 3D text-driven emotive audio-visual avatar, IEEE International Conference on Multimedia and Expo (ICME) 2008, pp. 1205-8
- Hao Tang, Xi Zhou, Matthias Oisio, Mark Hasegawa-Johnson, and Thomas Huang, Two-Stage Prosody Prediction for Emotional Text-to-Speech Synthesis, Interspeech 2008, pp. 2138-41
- Hao Tang, Yun Fu, Jilin Tu, Thomas Huang, and Mark Hasegawa-Johnson, EAVA: A 3D Emotive Audio-Visual Avatar, IEEE Workshop on Applications of Computer Vision (IEEE WACV ’08) pp. 1-6, 2008
People
- Dan Morrow
- Mark Hasegawa-Johnson
- Tom Huang
- William Schuh
- Renato Azevedo
- Yang Zhang
- Kuangxiao Gu
- Daniel Soberal