Overview
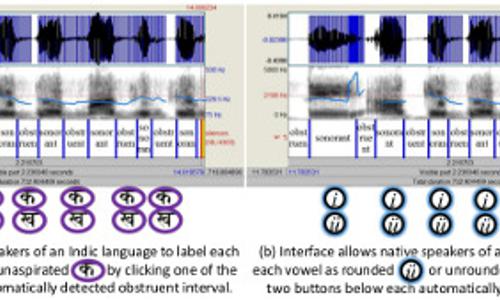
Mismatched crowdsourcing is the transcription of speech by crowd workers who do not speak the language. Non-native phoneme misperception can be modeled as a noisy communication channel. Error-correcting codes can be devised which factor speech transcriptions into phonological distinctive features, and “transmit” each feature through the “channel” (human transcriber) whose native language background gives her the highest probability of faithful transcription. Resulting transcriptions can be exploited in order to develop speech technology (automatic speech recognition) for languages in which there are no native language informants and no transcribed speech. In particular, this project will seek increases in the scale and robustness of mismatched crowdsourcing by using error-correcting codes to divide the transcription task, and by then distributing each sub-task to transcribers whose native language is one containing the distinctive feature requested.
Funded by NSF Award 15-50145.
People
- Mark Hasegawa-Johnson
- Preethi Jyothi
- Lav Varshney
Data
The following dataset was created as part of this research.