Overview
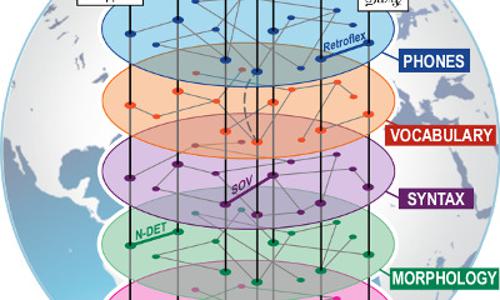
Knowledge about language relationships provides a wealth of information that can often substitute for, or complement, linguistic data resources. However, it should be encoded in a formal representation, ideally one that also offers principled methods and algorithms for utilizing this knowledge. Graphs and their associated algorithms have been explored in, e.g., machine learning, social network theory, or graphical models. Many graph-based algorithms have been analyzed both theoretically (e.g., they have approximation or performance guarantees), and within practical applications, thus providing a mature starting point. Second, weighted graphs yield a flexible representation in that weights can be specified either manually (when data is lacking), in a data-driven way, or both. Thus, a network of language relationships can accommodate both data-driven information derived from resource-rich languages as well as information from limited data resources, e.g., linguistic experts’ judgments. Third, graph-based learning approaches have the advantage of being able to utilize information from the entire graph. This means that nodes can influence one another even if they are not directly connected — information may flow indirectly between nodes, via connections through other nodes. A resource-poor language that is not directly connected to a resource-rich language can thus still benefit from the latter if relevant information can be propagated through intermediary languages. The Language Network: We informally define the LanguageNet as a set of graphs whose nodes represent languages and whose weighted edges represent pairwise relationships between languages. A given language is actually represented as a set of nodes, each of which corresponds to a level of linguistic description (syntax, morphology, lexicon, etc.). The information associated with a node can be thought of as either parameters (a vector of parameters for a given level) or data resources (a list of pointers to data resources available for a given level). Edges are defined between pairs of nodes. Edge weights represent parameter or data similarity, and since a LanguageNet is a set of graphs over the same node set, the relationships between two languages may differ for different linguistic levels.
People
- Katrin Kirchhoff
- Mark Hasegawa-Johnson
- Preeth Jyothi
- Leanne Rolston
- Gina-Anne Levow
Data
The following datasets were created as part of this research.
- Wikipedia-alphabet-based G2P
- Illinois LORELEI Ilocano
- Illinois LORELEI Odia
- Illinois LORELEI Sinhala
Useful External Links
Tasks
The tasks being pursued at the University of Illinois are:
- Task 5: Non-Native Phonetic Crowdsourcing of Incident Language Speech Data
- Task 6: Transfer Learning of Pronunciation Dictionaries
Non-Native Phonetic Crowdsourcing of Incident Language Speech Data
Objective: Methods will be developed for the rapid transcription of speech by non-native transcribers, and the high-accuracy interpretation of such transcriptions.
Approach: When a native speaker of language X attempts to transcribe phones in language Y, her perceptual confusions follow a probability distribution that can be estimated based on the tessellation and coarticulatory variability of the phone inventories in each of the two languages, and based on published models of second-language speech perception. Transcriber phone confusion probabilities can then be compiled to an FST (in order to model contextual effects). FST composition permits us to compute the maximum likelihood source-language phone string given one or more second-language transcriptions. We assume that native-language transcribers of the IL do not exist, but that we have some information about the IL phone inventory. Comparison of IL phone inventory to the inventories of languages in the LanguageNet permits us to estimate, in advance, the phone confusion probabilities that would be incurred by transcribers recruited from any particular high-resourced native language. For example, suppose it is known that an IL independently varies the aspiration and voicing of plosives (like Hindi), and that it also independently varies tongue fronting and lip rounding (like Turkish). Inference of the true IL phone transcription is improved by recruiting transcribers in both Hindi (or other Indian languages) and Turkish (or other languages that distinguish rounded vs. unrounded vowels with identical tongue position). We will (a) populate the LanguageNet with edges expressing the similarity of phone inventories across languages, and (b) use this information %Experiments will be performed using the seventy languages for which we %have untranscribed speech data, and using any speech data provided in %LRLPs. For each less-resourced language, we will use the LanguageNet to select non-native transcribers for an IL from languages with appropriately overlapped phone inventories, and (c) infer phone transcriptions for IL speech data using FST models with parameters optimized using transfer learning techniques. Transcribers will be recruited using standard crowdsourcing labor markets. Since ASR in well-resourced languages is cheaper than human crowd workers, the crowdsourced transcriptions of these data will be complemented by mismatched-language ASR transcriptions. In some cases, mismatched-language ASR may be adequate to estimate phone transcriptions of IL speech; methods based on active learning will be developed to determine which IL utterances need to be sent to human crowd workers for transcription.
Transfer Learning of Pronunciation Dictionaries
Objective: We assume that state-of-the-art grapheme-to-phoneme G2P models do not exist in an IL. In order to map from phone transcriptions to word transcriptions in an IL, it is necessary to apply semi-supervised transfer learning methods to infer a G2P. The task of inferring a G2P is made feasible by the assumption that the writing system or writing systems used by an IL are historically related to those of one or more languages already coded in the LanguageNet.
Approach: We assume that IL data include a small amount of text data, a small amount of speech data, and field-linguistic hypotheses about the historical origin of the IL writing system. We also assume that we have G2P mappings for languages in the LanguageNet that have writing systems historically related to that of the IL. We assume, further, that we have grammar-school textbooks and/or field linguistic descriptions sufficient to specify a prototypical rule-based G2P for the IL. Under-resourced languages are often historically under-resourced, and therefore have writing systems developed within the last few centuries, thus offering relatively high sound-to-symbol correspondence (lower “orthographic depth”) and improving the success rate of a prototypical G2P. Exceptions to the prototypical G2P will be hypothesized based on G2P models of related languages in the LanguageNet; either data or parameter transfer techniques can be used here. The prototypical G2P and exceptions are then compiled into an FST, whose edge probabilities are trained to find a small number of high-probability matches between the most common strings in available IL text data and available IL speech data (joint learning). Experiments in G2P inference will be conducted in seventy languages and in all languages provided in the LRLPs. In each such language, we will train the best possible G2P, using all available data including standard data for well-resourced languages. In each under-resourced language we will also conduct a sort of leave-one-out experiment, in which transfer learning is used to construct a G2P whose quality can be evaluated by comparison to the reference G2P.