Overview
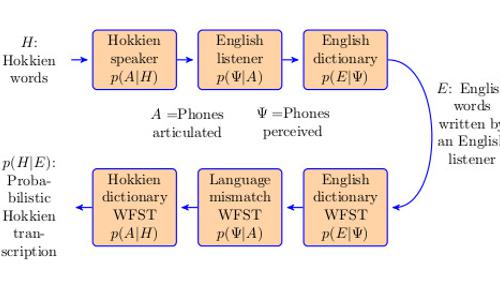
Widely accepted estimates list 6700 languages spoken in the world today. Of these, commercial automatic speech recognition (ASR) is available in approximately 80. Almost all academic publications describing ASR in a language outside the “top 10” are focused on the same core research problem: the lack of transcribed speech training data. In (Jyothi and Hasegawa-Johnson, AAAI 2015) we proposed a method called mismatched crowdsourcing that acquires transcriptions without native-language transcribers. Instead of recruiting transcribers who speak the language, we recruit transcribers who don’t speak it, and we ask them to transcribe as if listening to nonsense speech. Mistakes caused by non-native speech perception are encoded in a noisy-channel model: a finite state transducer (FST) with learned or estimated error probabilities. At JSALT WS15 we demonstrated that it’s possible to train ASR in this way. We propose to continue this research in Singapore because (1) under-resourced language data is more plentiful in Singapore than Urbana, and (2) leveraging Singapore’s unique global position, I2R is now one of the world’s leaders in speech technology for under-resourced languages.
People
- Mark Hasegawa-Johnson
- Nancy Chen
- Boon Pang Lim
- Preethi Jyothi
- Van Hai Do
- Wenda Chen
- Amit Das